
There are many workflow engines in the market, many data management ETL platforms, state of the art, AI driven, next generation entity resolution engines that create a controlled, efficient, risk management mitigation process. There are so many – all with the best algorithm/automation/insight/ efficiency that it’s impossible to distinguish most or see the value from new entrants. Or find a reason to change…with alignVu there is no change.
alignVu is a combined data and software as a service (DaaS & SaaS) that is a non-invasive ‘add on’ or parallel solution that monitors, reconciles and provides assurance and insight that your current process is accurate, complete, low latency end to end from sanction list, aggregator through to your existing integrated lists.
Everything alignVu does is visible through a set of dashboards, with deep drill down capabilities to enable business people from senior management, researchers, operations teams and data analysts to deep dive every report, update, reconciliation and latency gap alert.
- alignVu breaks the ‘hard coded’ dependency between data sets and screening platforms to make adding new or changing datafeeds or platforms simpler, faster with less risk and cost.
- alignVu delivers a ‘no code’ alignment, consolidation and integration as a one of assessment, migration service or as a secure continual service. You choose.
- alignVu provides transparent, real-time insight about datafeeds, their content, how they change, consolidate and the impact those changes have on day-to-day screening and investigation operations before they impact the business for real.
- alignVu has built in end-to-end reconciliation and auditing of mapping, translation, transformation, consolidation, integration and distribution down to each value in each field from provider to screening platform as a continuous reconciliation.
- alignVu dashboards provide end users and management with insight on changes from regulators, issuers, aggregators datafeeds and their impact as they happen.
Align
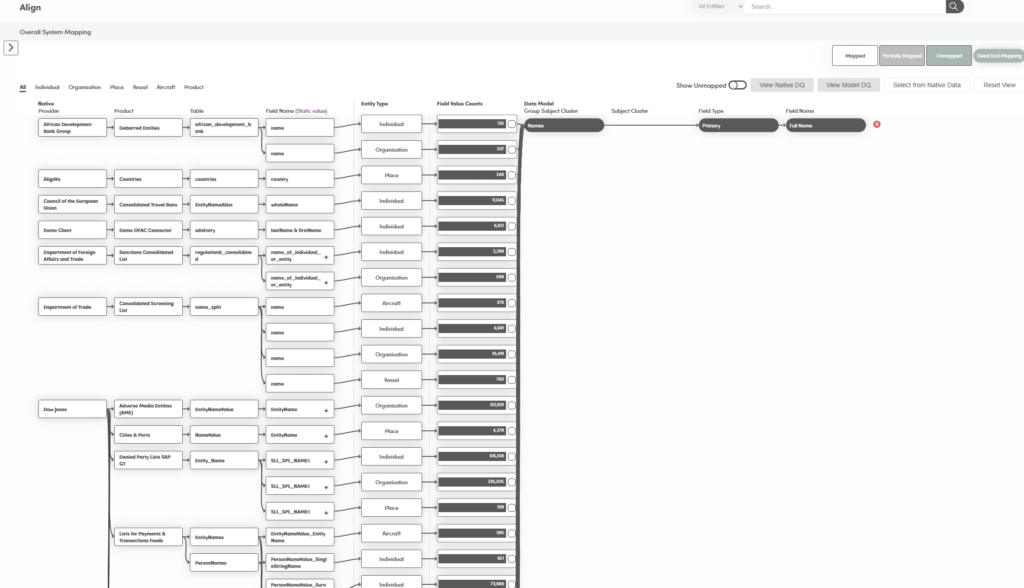
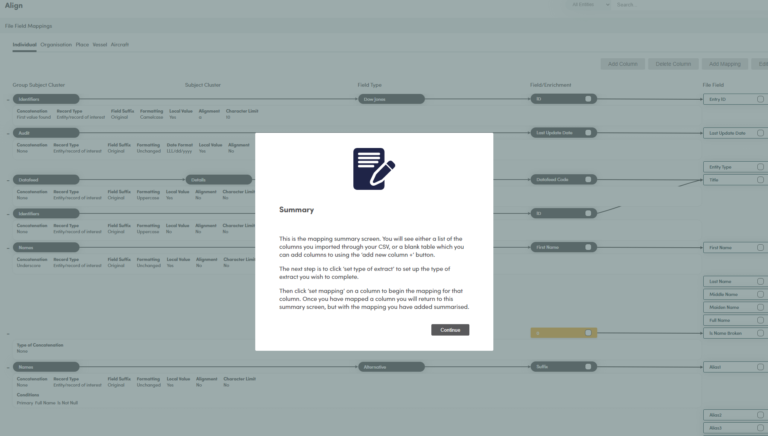
Maps each datafeed to a common model and dynamically onboards at field and field value, tagging each attribute with time of arrival, DQ assessments and (once fully aligned) builds runtime (hourly or scheduled or change driven) delta processing with continuous audit and reconciliation.
By mapping to a common model every datafeed is assured of having all of the additional fields and values required to be able to create delta records, indentify change values and track them through
a continual audit process.
Real time updates (hourly for regulators, on publication for aggregators (every 4 hours max)) with DQ validation and variance detection.
30/60/90 day rolling history.
All datafeeds and list are mapped and validated ‘ready to go’.
Monitor
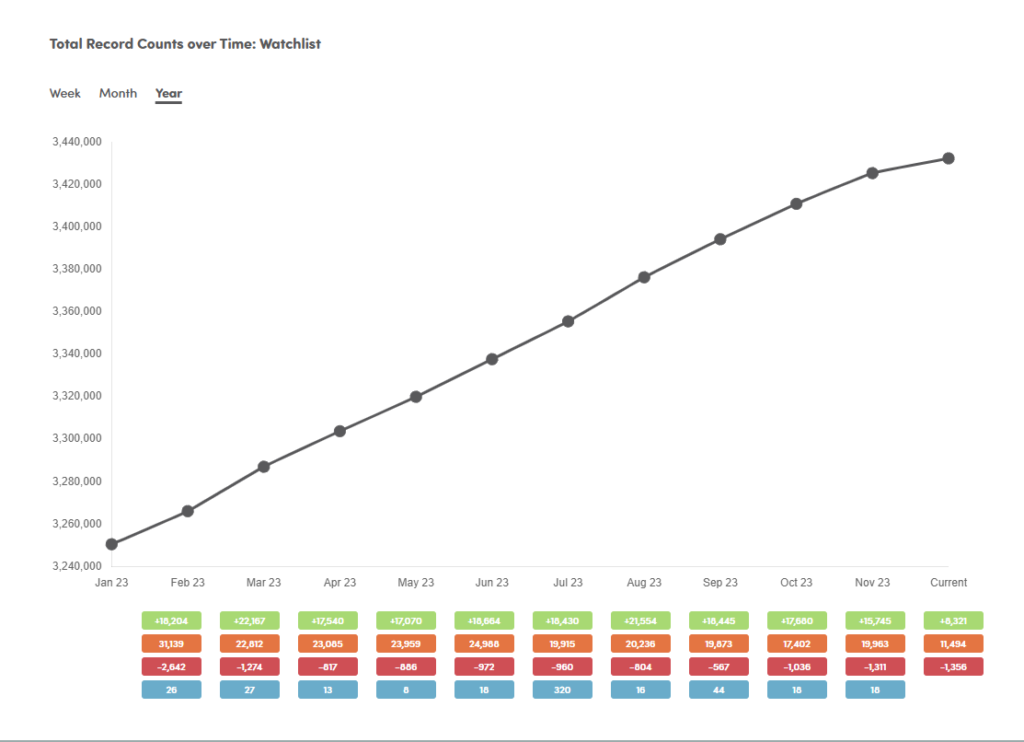
Dashboards provide detailed monitoring of jursidiction, country of focus, country of record, provider, list of each record, changes to that record, updates at record, field and values within fields.
Detailed tracking and reconciliation from provider publication to provider with continuous reconciling and audit process at each step – 30/60/90 day online history.
Ability to include internal watchlists and screening data feeds to create end to end monitoring, gap analysis and aggregator performance vs SLA.
Assess
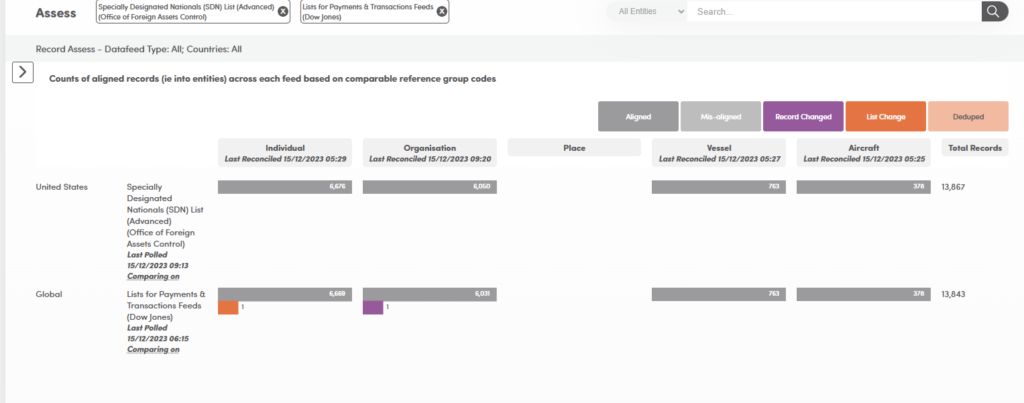
Each damaged is assessed individually, but also reconciled from its originating source through to aggregator, internal list and screening datafeed (when client adds).
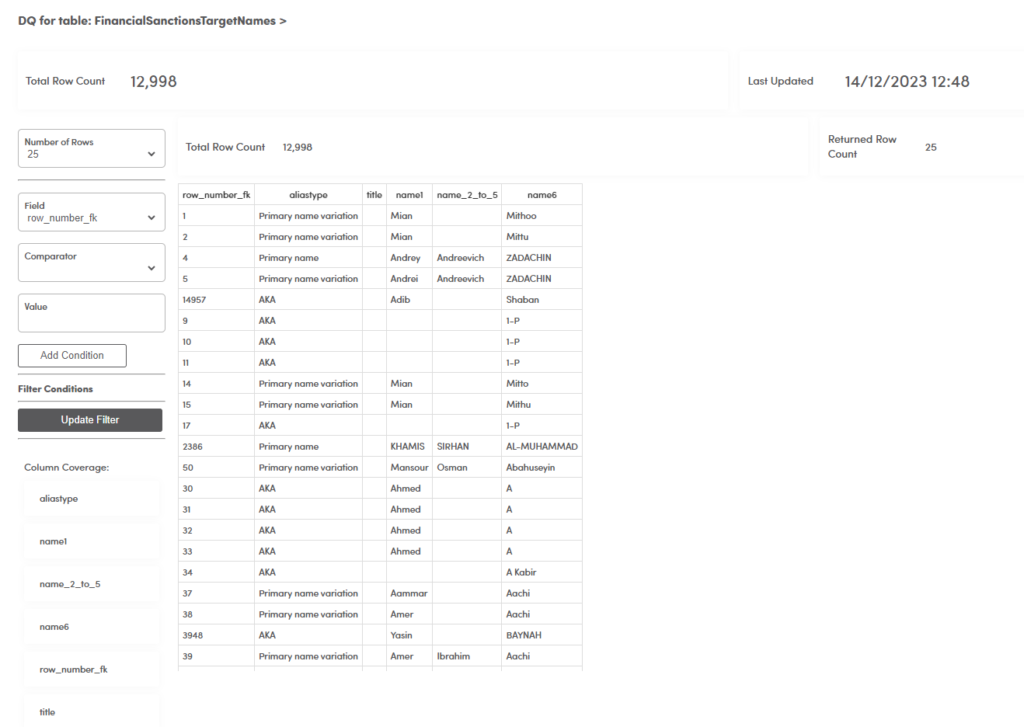
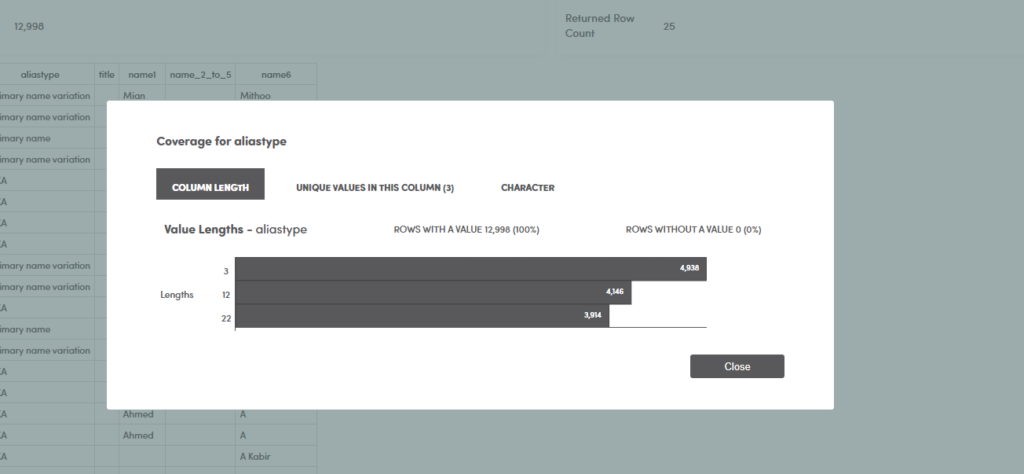
Field level attribution enables tracking and reporting of each record, field and value for accuracy and completeness and identifies where there is a real gap or one that is created by latency between datafeeds.
Clients can run their own gap analysis, check list mapping completeness, manage changes and leverage an end to end audit process as a one-off or continual process.

Consolidate
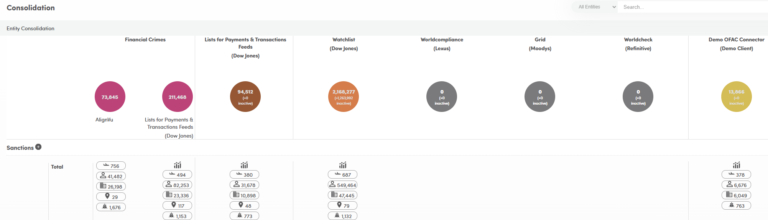
alignVu can augment an existing screening process or can simplify and accelerate a new implementation.
Our pre-defined connectors are available for all the leading screening platforms and if we don’t have one, we will supply as part of your subscription.
alignVu augments existing processes by either running in parallel against a schema, but supplying insight, transparency, audit trails and historic analysis about your datafeeds.
Impact
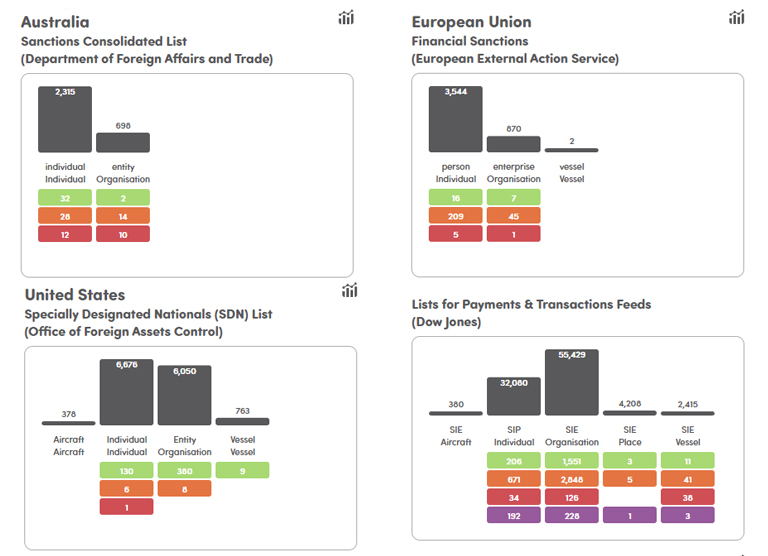
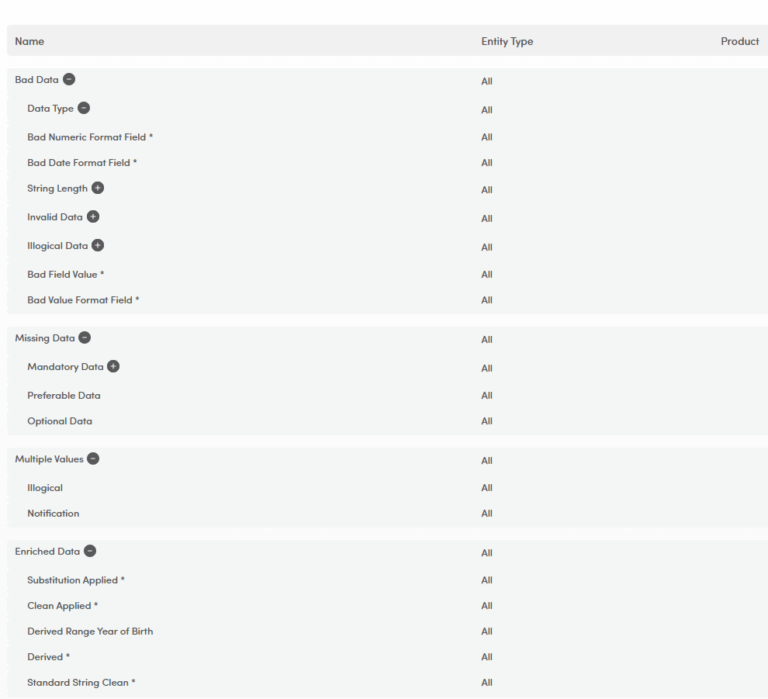
Summary assessment of end to data coverage (where client schema added) which shows at record, field type and value the impact not only of mapping differences, but changes as they occur.
alignVu can define significant change down to field level, allowing users to determine the type of update that is material to their process – whether it is a mandated screening filed or additional information or a technical update.
alignVu creates delta reports for all feeds, even those only supplied in full as bulk, which can not only report number and type of changes, but also additional terms or where a change doesn’t create any new terms – to enable decisions of processing based on evidence.
Connect
Deduplication of records per datafeed to single entity profiles, based on common identifiers between the aggregated data feed (Dow Jones Lexus Nexus, Refinitiv and Moody’s).
Common data structure and entity for all originator data feeds – sanction lists, GLIEF, Regulators, Corporate registries.
Comparative analysis of supported aggregators to enable end users to compare coverage, performance and value adds between existing providers.
Key features
Real Time End-To-End Monitoring
Real-time end to end auditing and data assessments of multiple regulator, aggregator, and client lists/datafeeds to identify data gaps, anomalies and possible improvements with both view and historical audit trails of what changed, when and the latency of the changes flowing through to client adoption from publication.
Datafeed/List Alignment
Datafeed/List alignment, enrichment and change based consolidation that connect to existing data management, integration, workflow/KYC/CDD and screening platforms through connectors that provide ‘plug and play connectivity.
Non-Invasive Process Intervention Add On
Non-invasive process intervention ‘add-on’ that creates aligned, consolidated datafeeds/lists on a one-off, schedule, change or update basis – consolidated, filtered and impact assessed – based on assessment rules, standardised to client and platform schema requirements.
Plug and Play Realtime Dashboards
Plug and play, real time, dashboards with pre-aligned original source and aggregator lists ready to use.
Evidence Based Value Add
Evidence based value add and integrity of data service provided through field level attribution combined with change and latency tracking to provide real differentiation.
Operational Assessment
Operational assessment of comparative data quality and deduplication monitoring against originators, aggregator, and client lists with impact assessment of updates, changes, coverage gaps and velocity differences.
Historic Audit Trails
Historic audit trails provide 30/60/90-day profile tracking to enable investigations of who/what and when a change or a profile was happened and applied at field value provenance levels.
End-To-End Monitoring
Combining client lists and screening files embeds the data service at the heart of their clients through end-to-end monitoring and data assessments.
Linked Profiles
Linked profiles in structured relationships that fill in the hierarchy through adding related to related owners, family members, close associates, and common locations.
Add On Connect
Connect is provided as an ‘add on service’ that is non-invasive, is data ready with originator and provider data – subscribe, add licence credentials, and start using. Client lists and intervention-based extracts can be additional add-ons.
Real time monitoring and reconciliation assessment of regulator, aggregator, and client lists/ datafeeds to identify data gaps, anomalies, latency and reconcile each list, record field and value for attribution, differences, changes, updates, velocity and latency of updates from origination through to client application.
AlignVu is designed to work with existing datafeed integrations, screening, investigation and workflow platforms and add value through streamlining and validation the lists of target records of interest screened.
alignVu DaaS service is a non-invasive data processing, analytic and insight engine built around a relational data model that can distribute from source to you directly or provide monitoring, reconciliation and deep insight in parallel to your existing processes.
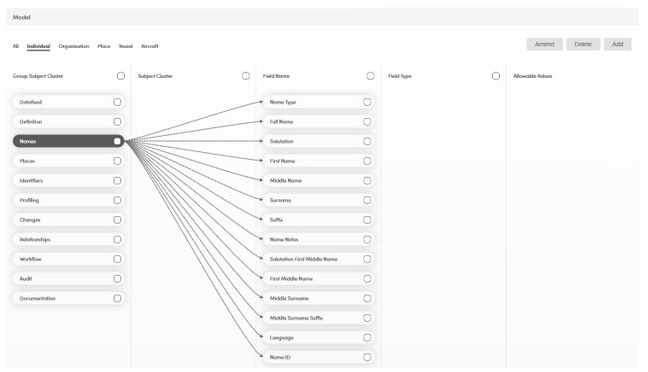
- alignVu core mapping engine converts Dow products, sanctions list provider lists to its relational data model
- Each mapping seeks to map the same value to the same field for the same entity type in order to drive accurate comparability.
- alignVu creates a unique reference group code for each sanction list provider list, which it links to both the Dow Jones Equivalent provider code/ ref group code, but also links again in the client datafeed.
- The mapping and the link of reference group codes is what drives comparability and all the analytics - so accuracy is critical
- alignVu is not a matching engine, nor is the cost benefit of AI (training set v relevancy and manual decisioning) apparent to us, so alignVu runs ID to ID for comparability and where on the sanction there is no ID, alignVu use relevancy to suggest records that are the same for human decision to link and create an Id to ID mapping, but not an entity
- Each sanction list provider has its own schema, level of DQ and all vary from the Dow Jones models, which means as part of the mapping process alignVu defines rules based on analysis and (sometimes assumptions) - which need to be verified
- The monitoring, reconciliation and assessment is driven from the mapping process so our mapping has to accurate, transparent and identify where variation or change (or error) requires an update. alignVu uses DQ and variance analysis to do so.
- For Dow Jones customers who have already integrated a screening (say NiceActimize) feed - there is no way they will disrupt that process and for the big 24x7 shops no way they’d add several hours to an existing process. alignVu doesn’t need them to change anything.
- alignVu is non-invasive, zero implementation for existing Dow Jones customers because alignVu runs in parallel constantly processing copies of a complete set of Dow Jones Risk solutions.
- alignVu also has preconfigured connector to leading sanction/AML screening solutions, which means all alignVu needs is a copy of schema and a one-time version of the integrated dataset and we do the rest
- alignVu can also compare multiple data providers - to enable clients to single source or multisource -
- This means that for existing Dow Jones screening partners and clients, alignVu offers baked in value add on analytics, insight, change tracking, validation and comprehensive data quality assurance
- The same can be provided for the clients of other Risk Data providers on request
Our DaaS processes three types of data
- Data we Process that we Make Available to ALL from official government and reference data providers - available at no cost in their original form
- Data our Client has Licensed from a Financial Crime, Sanction List or reference Data Aggregator
- Data we Process that belongs to our Client
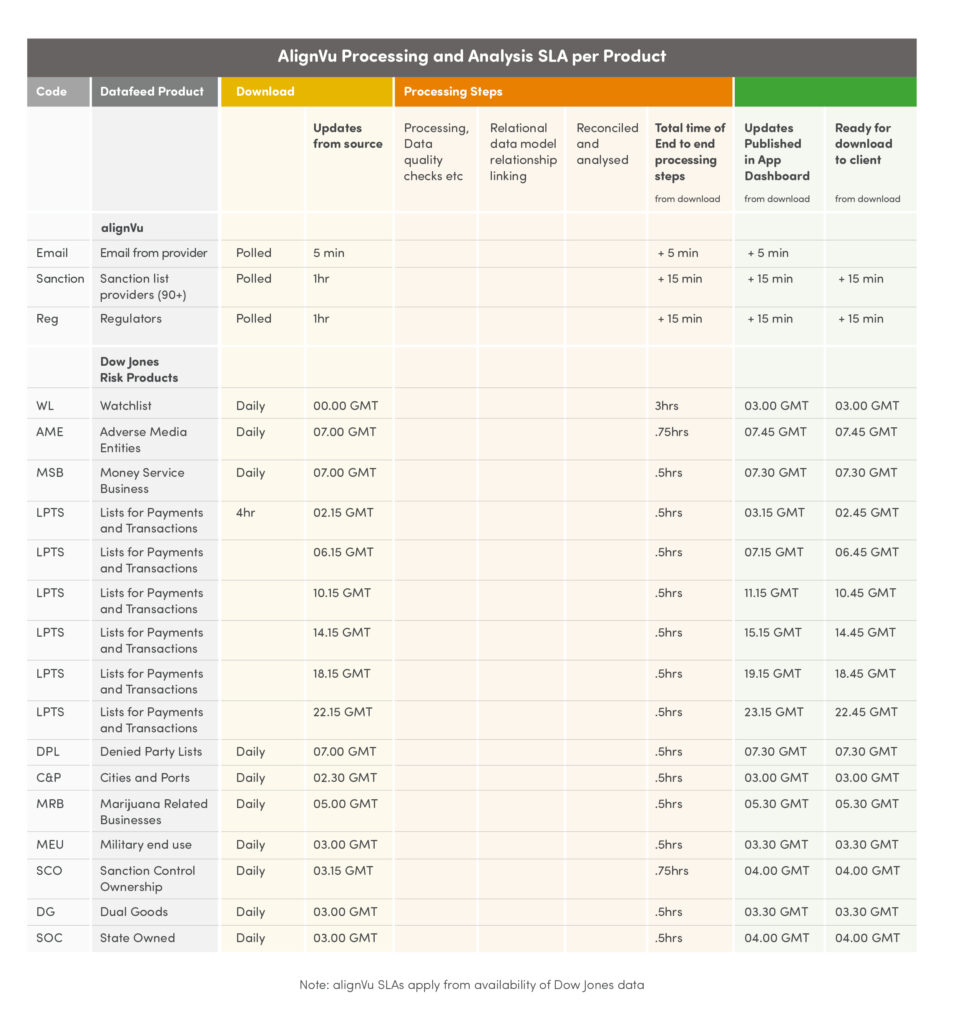
alignVu is also a Data As A Service that provide continuous data reconciliation and continuous distribution
The Data
Any processor of data, where they process multiple sources of primary data face data quality, curation and alignment challenges. The more sources processed, the more complex the choice between reduce the common set fields in standardised schema to preserve source attribution or start to transform/transliterate and augment to enable the data set to usable becomes. Attribution, validation and how close the real-time the data source is defines how reliable a data source is. The value of a 3rd party aggregator is the active curation of data – ensuring quality, completeness, consistency and the ability to deliver that quality in a timely manner. And provided the price isn’t creating a different version of that primary data.
Transparency
Transparency in mapping, alignment and standards is critical Every primary data source have differences in structure, content, freshness and standards. It’s a problem to create a standard model from primary sources where the data is ‘unique to that feed’, and providing that same data to end users – with differing systems, models and requirements adds another level of challenge. There is currently no ‘one model fits all’, so mapping standards, transparency about transformation need to extend through to the end user platforms. With sanction data, the challenge multiplies as primary sources overlap or republish other primary sourced data that has been legally adopted (I.e. UN sanctions). Mapping the same record of interest from multiple primary sources, managing the updates as those sources structurally evolve, ensuring that every primary source is reconciled and can be shown to be so at every stage, update, change, latency differences and record overlaps requires expert curation, process and monitoring.
Audit trails
Audit trails that can confirm current state but track latency through to end user are a critical success factor in data governance End to end audit trails from primary source, through aggregators, processors and to being able to reconcile, monitor and extend the audit trail to the end user platform creates operational integrity
Common standards
A common standard in data, its description creates utility saves a world of pain, but getting there…The destination is unquestioned, the journey from legacy land in implementing those standards is much more than a firm wide transformation plan. Being able to continuing doing business coherently, with a technology stack in various stages of transformation is a fundamental in being able to afford and sustain the journey.
Sanctions data
Sanctions data is critical data that needs to be actioned when its published. Near real-time updates of sanction lists be it an addition, delisting or changes to those lists remains a challenge due to the vast majority of sanction lists still being available in a bulk, full file with accurate communication from government regulators being random from all but a few and even with those there are often significant time differences between notification and those changes appearing on a datafeed. This means not only velocity challenges, but being able to apply only updates without having to re-process entire data sets is a key capability in achieving near-real time and being able to ensure that any latency resulting from the data provider has a full audit trail.
Data quality
Data quality needs a dataset perspective and where there are multiple overlaps between datasets the flow of records from one to another is also a key issue. We live in a data-driven world, and you cannot identify bias, systematic data-quality issues or key insights by looking at individual records. Simply passing on a mapped version of an individual record will fail to identify if it is a duplicate or has data that makes no sense in the context of the wider dataset. Data must be continually assessed across the whole dataset, comparing not just how an individual record has changed, or whether it conforms to a schema, but how the dataset as a whole has changed.